🍭 GRPO's Limitations for Reasoning Tasks
I've been experimenting with reinforcement learning finetuning and I tried to finetune a Qwen2.5-1.5B-Instruct base to play wordle, using GRPO, and I found some limitations, so this is a writeup on why I think grpo may not be the best technique for reasoning.
Note: I'm still learning so if there are already solutions or work arounds, or if i'm missing anything obvious, feel free to let me know and I will update this post!
Limitation 1: Reward Ambiguity
Complex reasoning problems need multiple reward signals, so we create multiple reward functions for each criteria. For example in my wordle project, I wanted to reward completions based on:
- following xml format - completions are rewarded if the reasoning is provided between <think> tags and final guess is inside <guess> tags
- followed past guess feedback
- guessed word is a valid word
- guessed word is a 5 letter word
- final word accuracy
And all rewards from each reward function are summed up and collapsed into a single reward signal (R1, R2, R3).
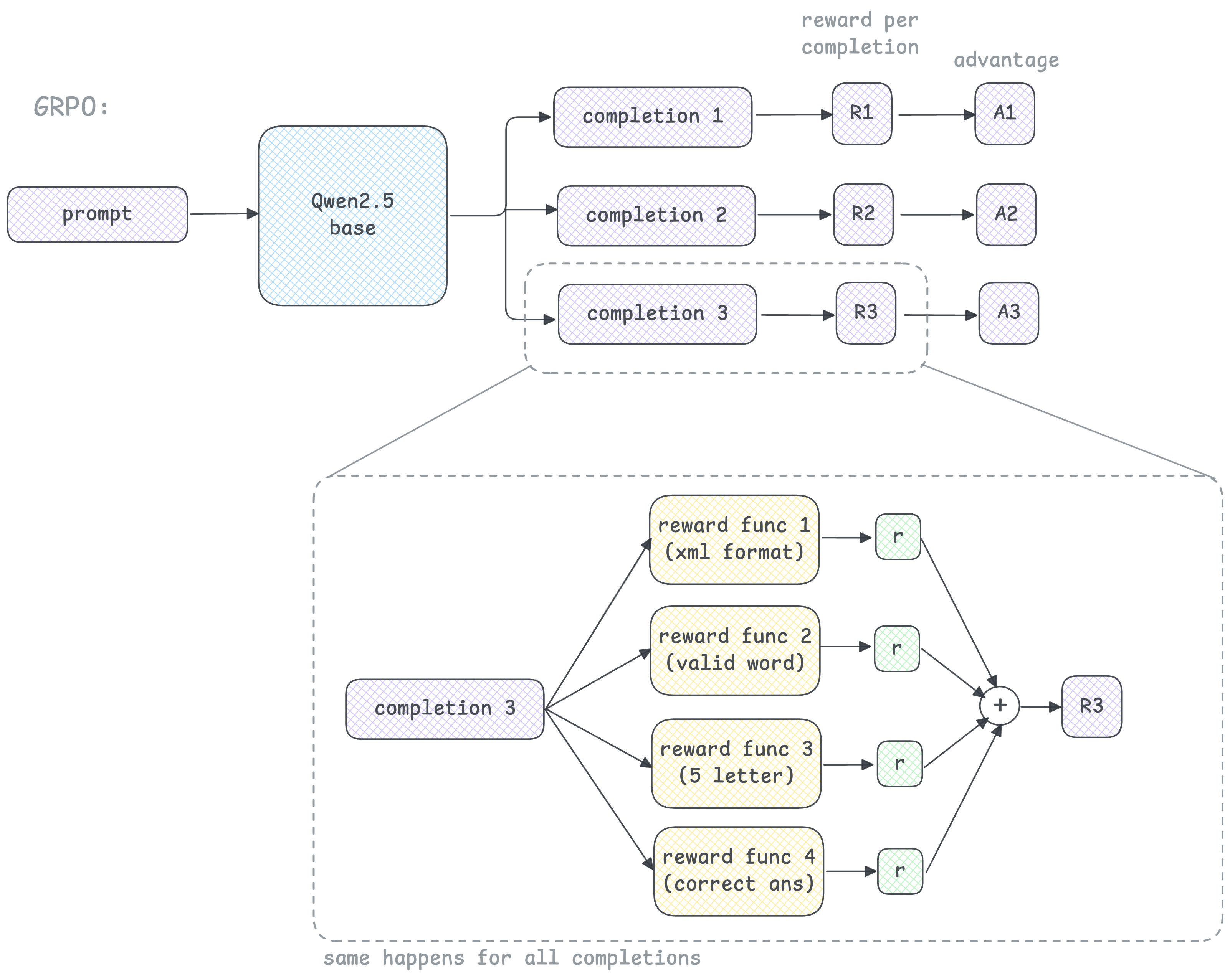
The issue here is that there is no way for the model to know *what part* of its behavior it is being rewarded for. A completion could have received high rewards for following past guess feedback perfectly, but penalized heavily for not following xml format, or guessing an invalid word. Even though we write seperate reward functions for these, all output rewards are being added up to represent as one reward signal per completion. So how would the model know if the reward is for getting the right answer, reasoning clarity or just proper formating?
Even if we were to adjust magnitudes of the different reward components, the model still only sees the total scalar reward.
Limitation 2: Scalar Feedback
I also noticed that for reasoning tasks, GRPO discards any intermediate textual feedback, because what’s fed into the model is just a numeric reward signal.
For example take a look at the outputs I printed from a wordle training run that shows if each completion follows previous guess feedbacks:
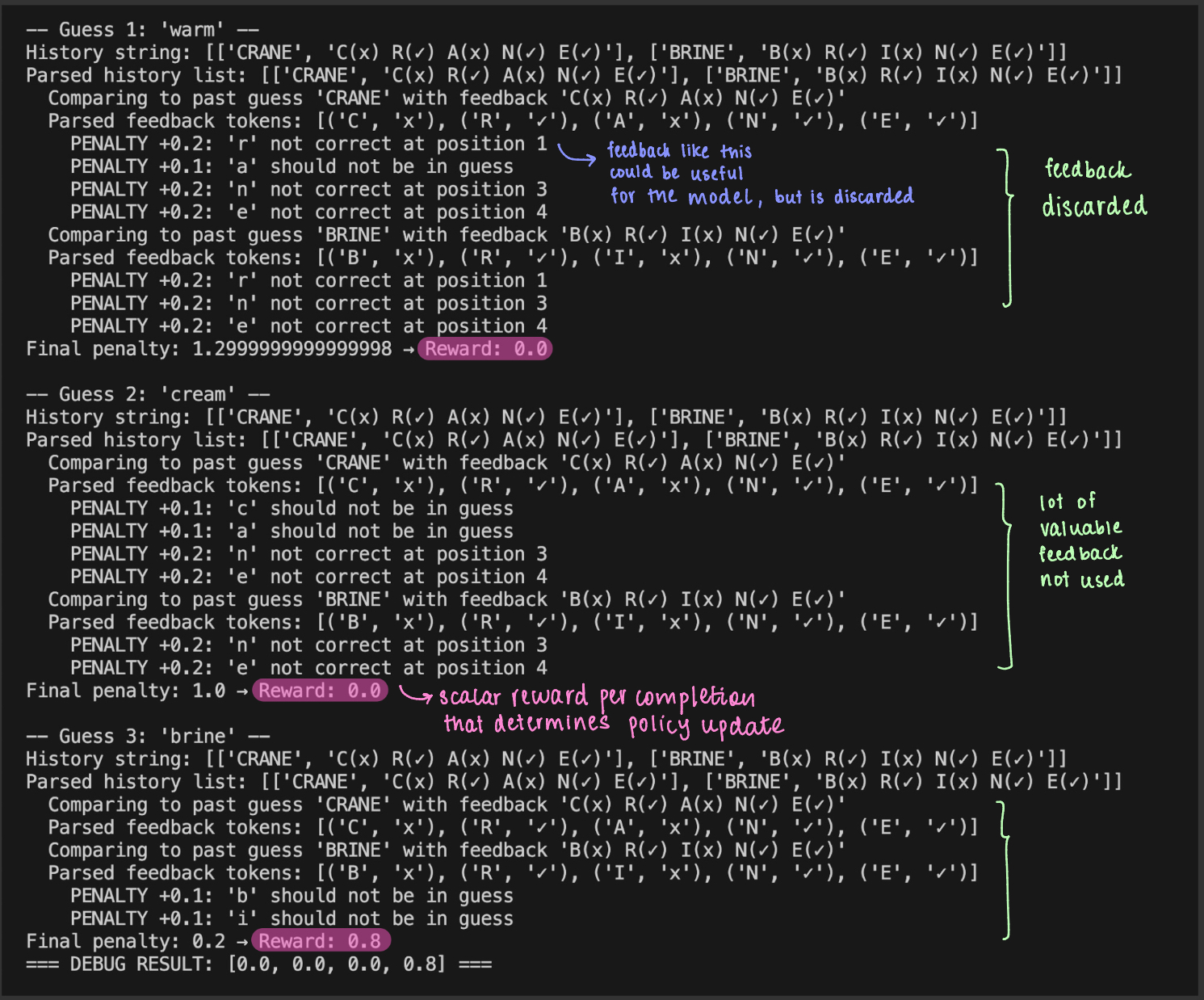
As you can see in this image, there is a lot of useful text feedback like "‘c’ should not be in guess", "‘n’ not at correct position 3", etc. that the model could benefit from. But this feedback cannot be used anywhere by the model to update its policy, since it is abstracted by a scalar reward.
The GEPA paper also acknowledges this limitation of grpo and proposes prompt optimization instead.
Limitation 3: Multi-turn reasoning
Another bottleneck I'm trying to explore more is multi-turn reasoning using GRPO. This part has been discussed in this thread here and here, and I wanted to elaborate a little more because I noticed this issue while trying wordle in multi-turn.
The reason this is a bottleneck is because after each turn the feedback is fed back into the base model as a prompt, and this results in exponential forking, which makes grpo in multi turn painful to work with. See image below:
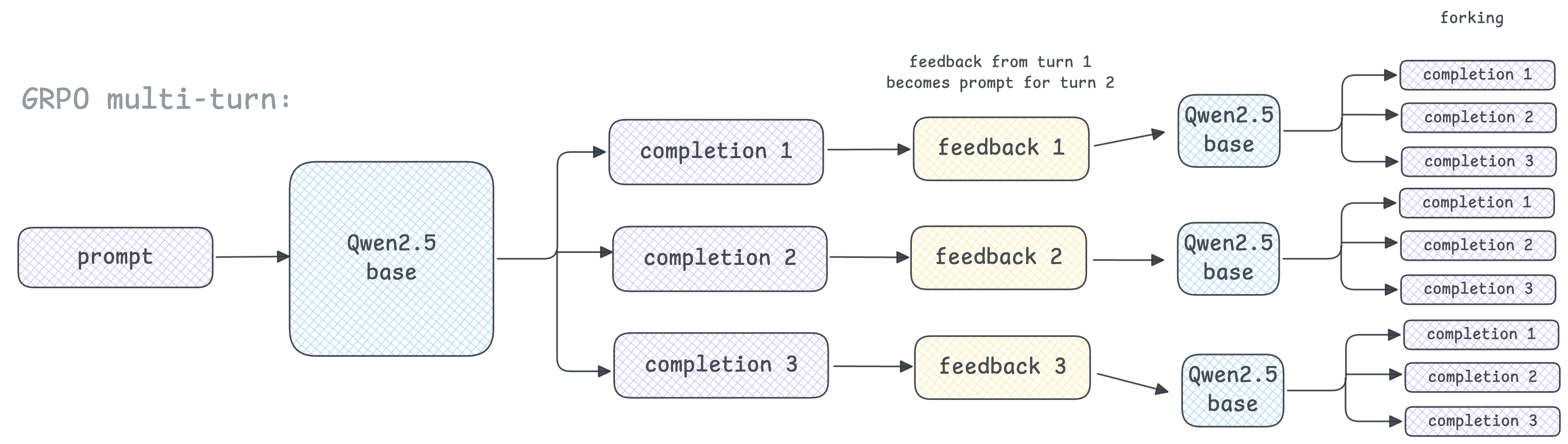
The problem here is that there is no baseline rollout to compare rewards against.
Takeaways
GRPO works well for single turn reasoning tasks, like training on GSM8K dataset which are single turn math problems. But it breaks for multi-turn training. We could also possibly be better off using intermediate textual feedback along with scalar rewards.
References
- Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y. K., Wu, Y., & Guo, D. (2024). DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv. https://arxiv.org/abs/2402.03300
- @willccbb (2025) On multi-turn GRPO forking. X(formerly twitter), https://x.com/willccbb/status/1954074226014794182
